注:本文虽然以瑞芯微RK3588 SoC进行示例,官方理论可支持瑞芯微其他系列SoC:RK3562、RK3566、RK3568、RK3576、RK3399PRO、RK1808、RV1126、RV1126B、RV1103、RV1106、RV1109等,参考本文去实现吧
前言:
本文为精简版:需要有一定视觉部署经验,yolov8_rk3588训练、转换、部署全流程
本人踩了3天坑摸索出来,撰写文章不易,望各位看官留赞,虽说是精简版,只是字数少与排版更好观看,有一定程序经验的都会看的懂
环境准备:
- 瑞芯微魔改的yolov8环境:airockchip/ultralytics_yolov8:新 - YOLOv8 🚀 (训练、转化onnx的环境)[PC电脑win11]
- 瑞芯微的rknn-toolkit2【v2.3.2版本】:airockchip/rknn-toolkit2(rknn模型转化的环境)[PC电脑ubuntu22.04]
- 瑞芯微的rknn_model_zoo:rknn_model_zoo(rknn模型转化的代码)[PC电脑ubuntu22.04]
注:开发板部署直接跳到第四章节即可 | 【rknn-toolkit2只能在linux环境下使用】
一、训练
<1.1> 环境配置:下载瑞芯微魔改的yolov8环境,通过PyCharm打开代码(请严格按照步骤)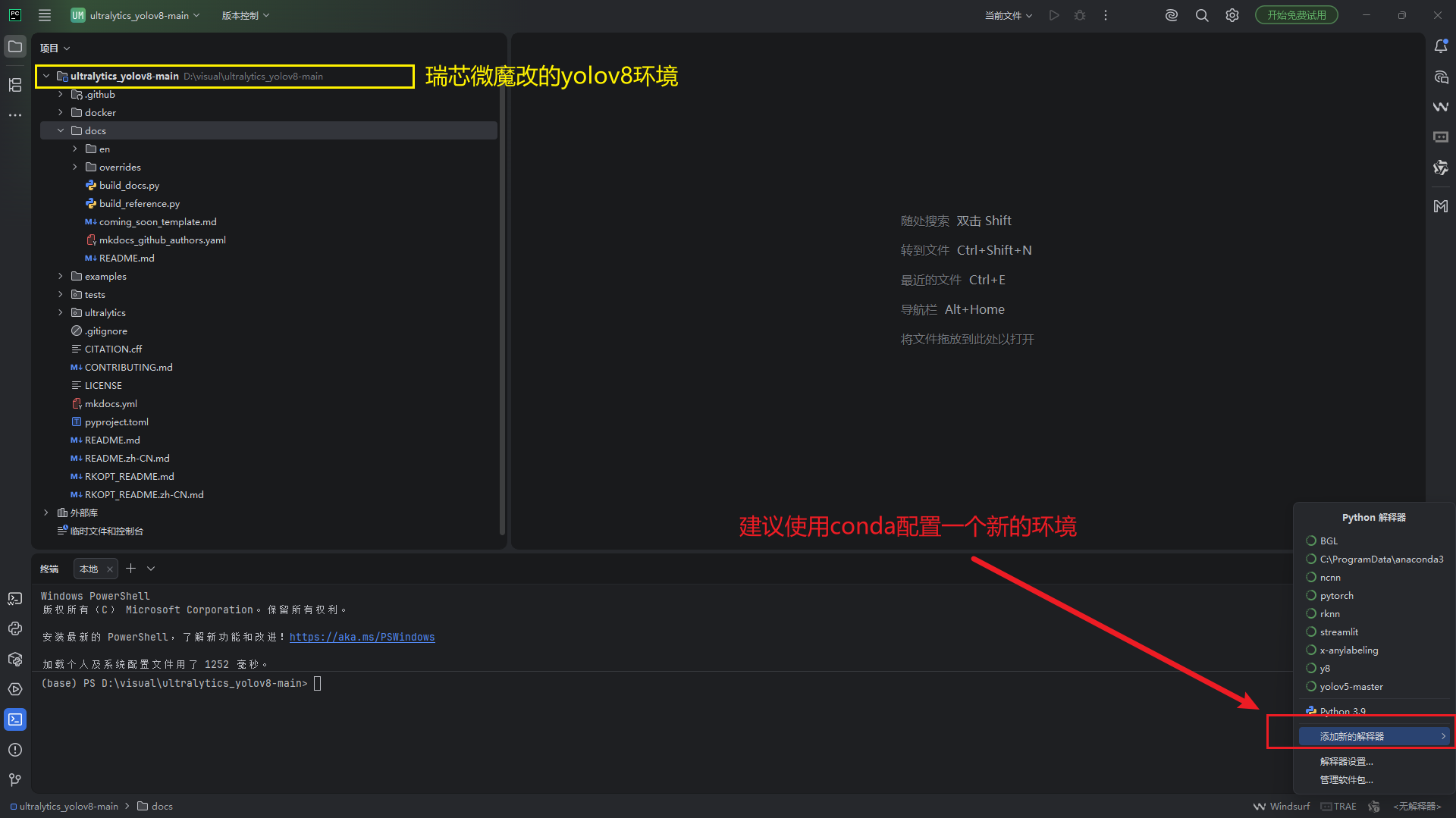
<1.2> conda配置一个新的环境(python3.8-3.12)【我这边用的python3.10版本】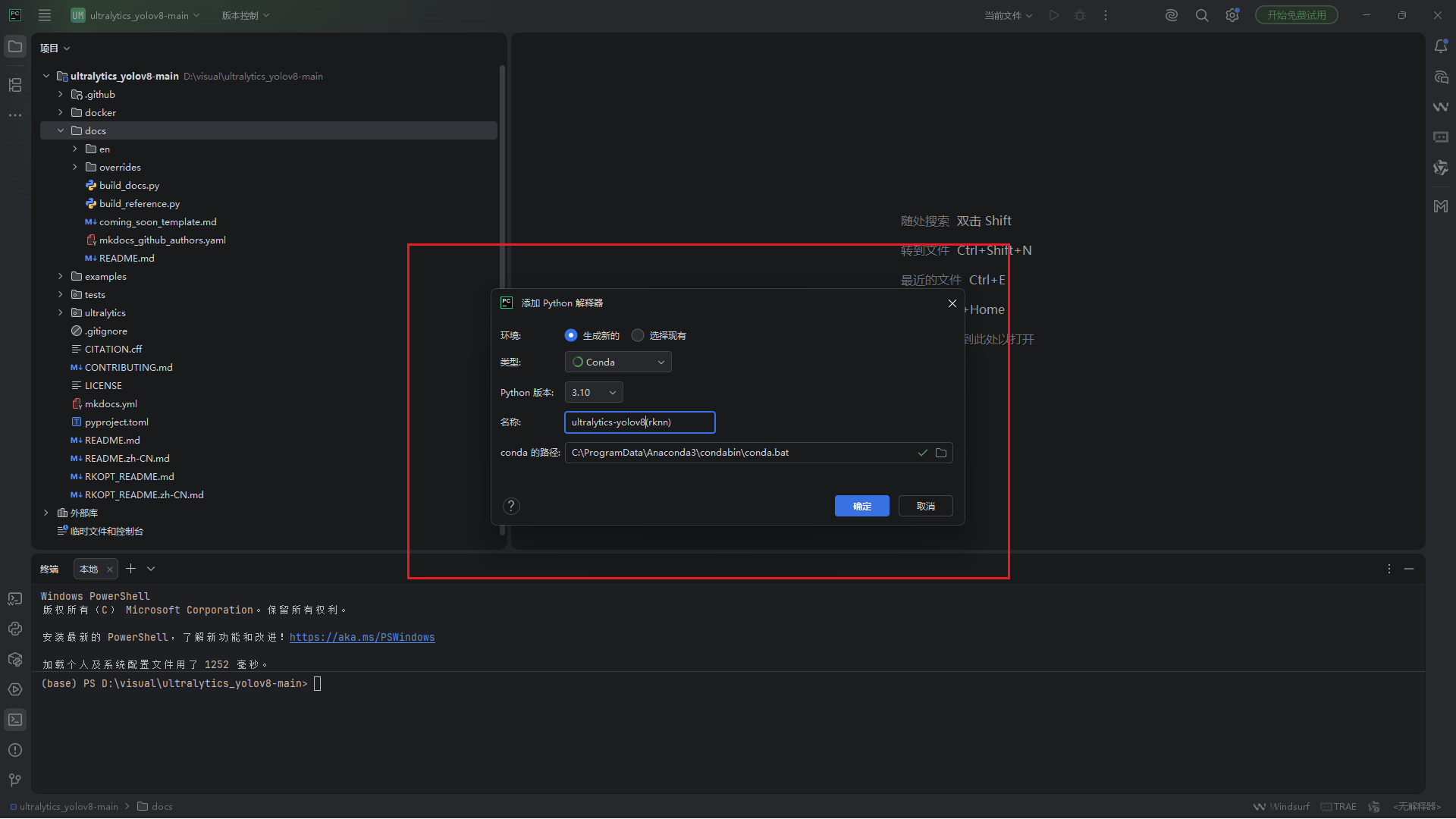
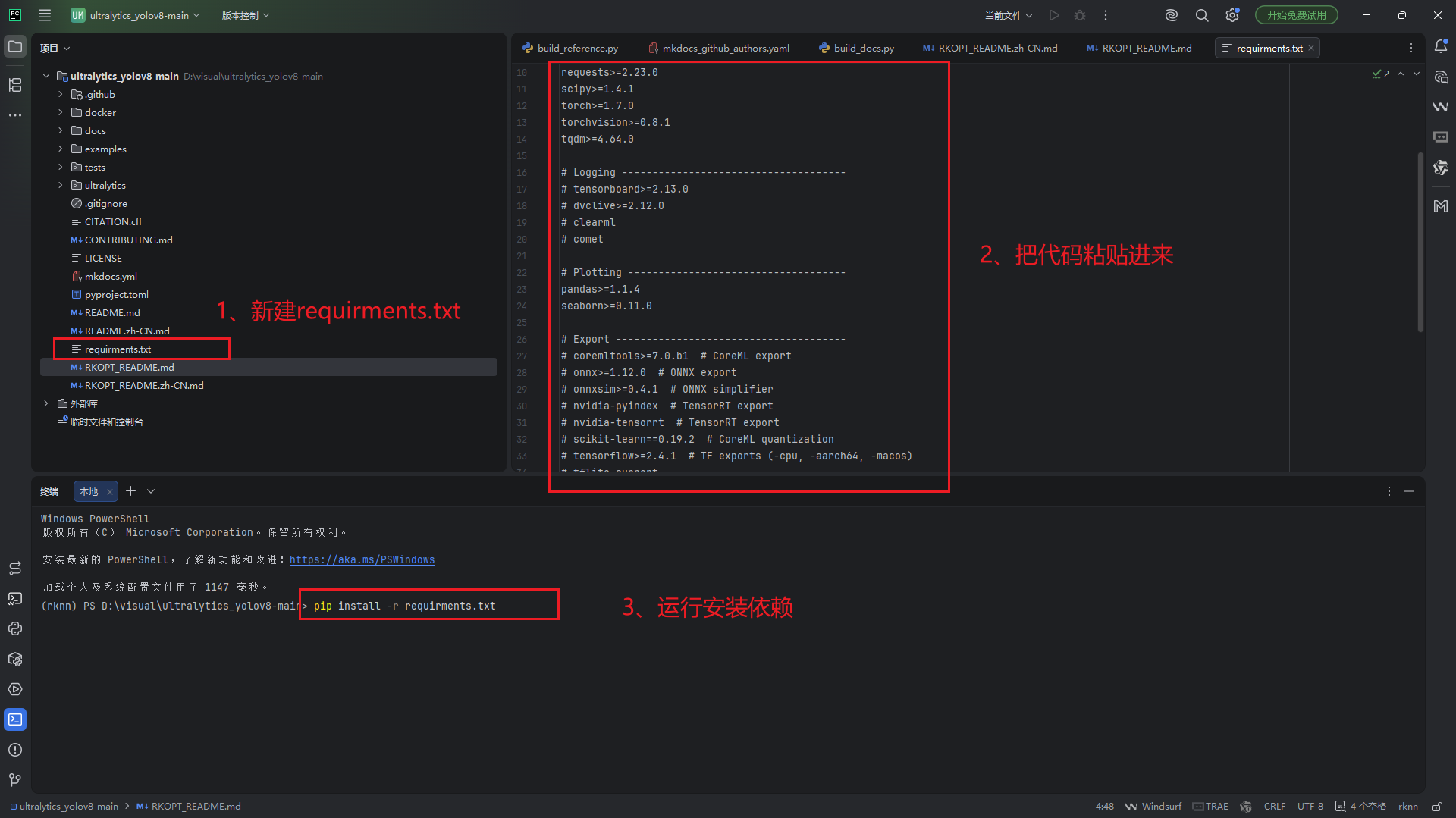
<1.3> 新建一个requirments.txt文件,将下面代码粘贴进去,并运行pip install -r requirments.txt
# requirments.txt
# Ultralytics requirements
# Usage: pip install -r requirements.txt
# Base ----------------------------------------
matplotlib>=3.2.2
numpy>=1.22.2 # pinned by Snyk to avoid a vulnerability
opencv-python>=4.6.0
pillow>=7.1.2
pyyaml>=5.3.1
requests>=2.23.0
scipy>=1.4.1
torch>=1.7.0
torchvision>=0.8.1
tqdm>=4.64.0
# Logging -------------------------------------
# tensorboard>=2.13.0
# dvclive>=2.12.0
# clearml
# comet
# Plotting ------------------------------------
pandas>=1.1.4
seaborn>=0.11.0
# Export --------------------------------------
# coremltools>=7.0.b1 # CoreML export
# onnx>=1.12.0 # ONNX export
# onnxsim>=0.4.1 # ONNX simplifier
# nvidia-pyindex # TensorRT export
# nvidia-tensorrt # TensorRT export
# scikit-learn==0.19.2 # CoreML quantization
# tensorflow>=2.4.1 # TF exports (-cpu, -aarch64, -macos)
# tflite-support
# tensorflowjs>=3.9.0 # TF.js export
# openvino-dev>=2023.0 # OpenVINO export
# Extras --------------------------------------
psutil # system utilization
py-cpuinfo # display CPU info
# thop>=0.1.1 # FLOPs computation
# ipython # interactive notebook
# albumentations>=1.0.3 # training augmentations
# pycocotools>=2.0.6 # COCO mAP
# roboflow
<1.4> 使用开发者模式安装ultralytics,在项目的根目录下终端输入 pip install -e .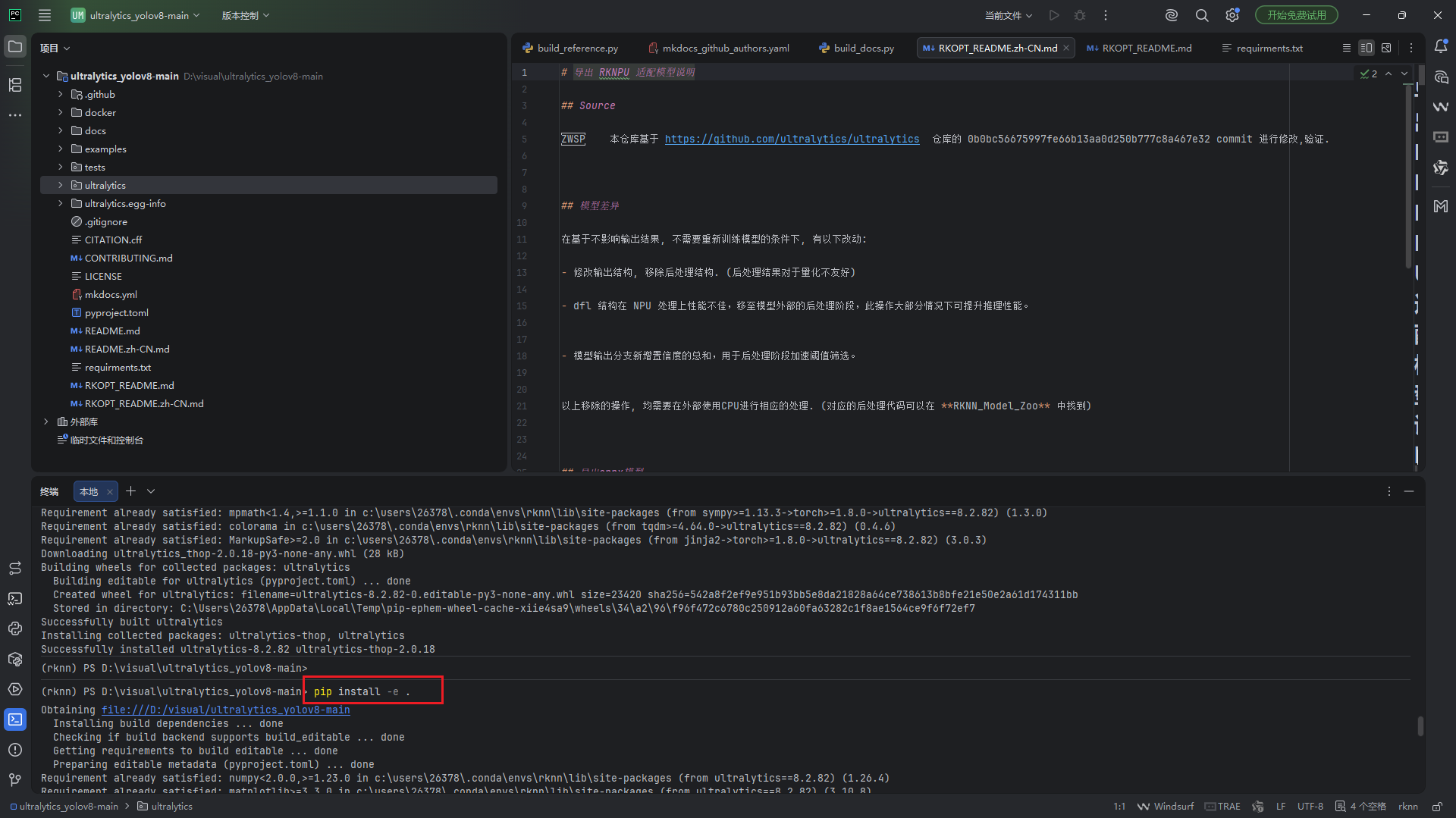
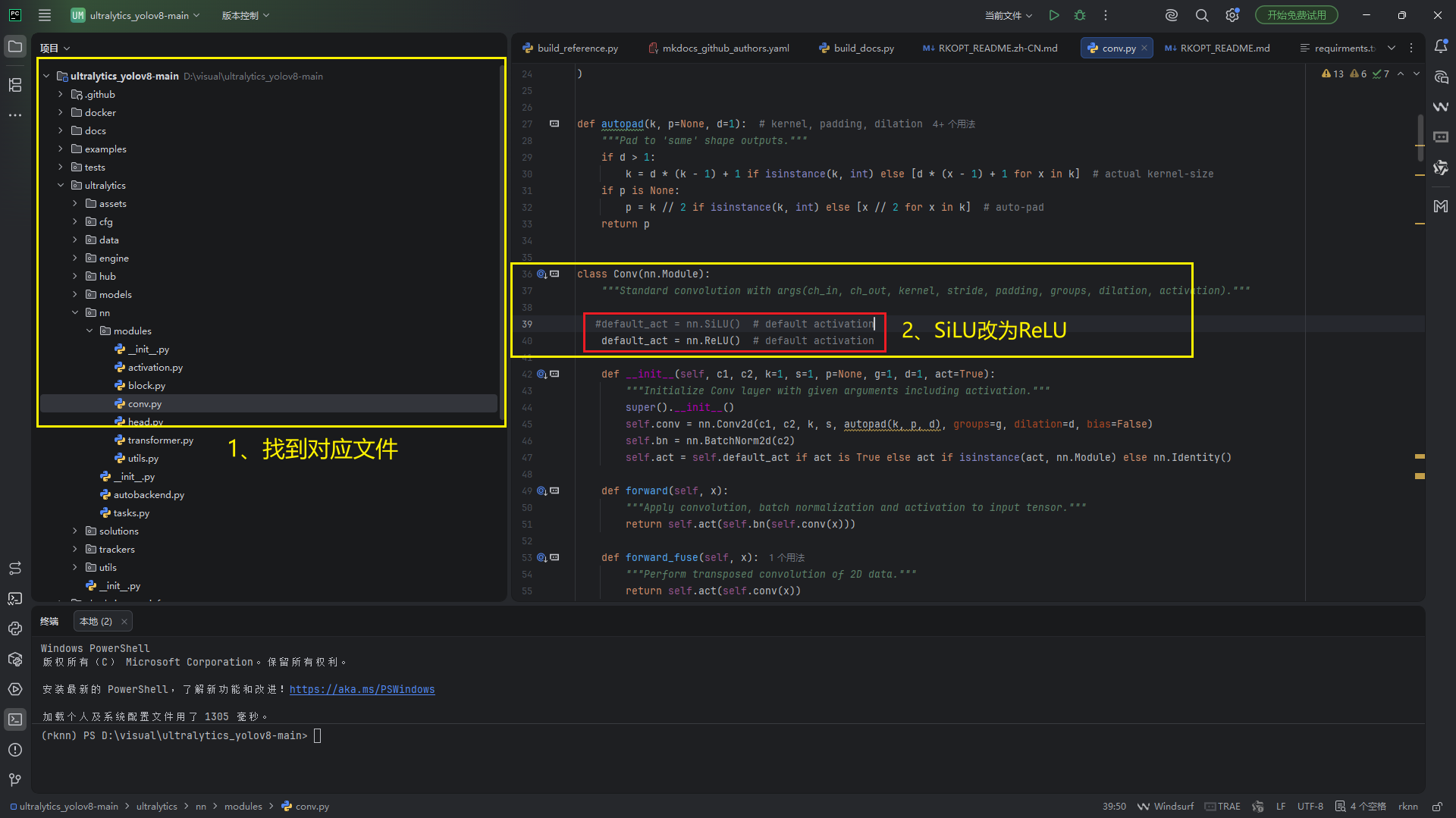
<1.5> 修改激活函数SiLU为ReLU(作用:开发板上推理变快)
- 文件路径:ultralytics_yolov8-main/ultralytics/nn/modules/conv.py
- 代码位置:Conv类的default_act = nn.SiLU() # default activation
修改代码改为:
default_act = nn.ReLU() # default activation
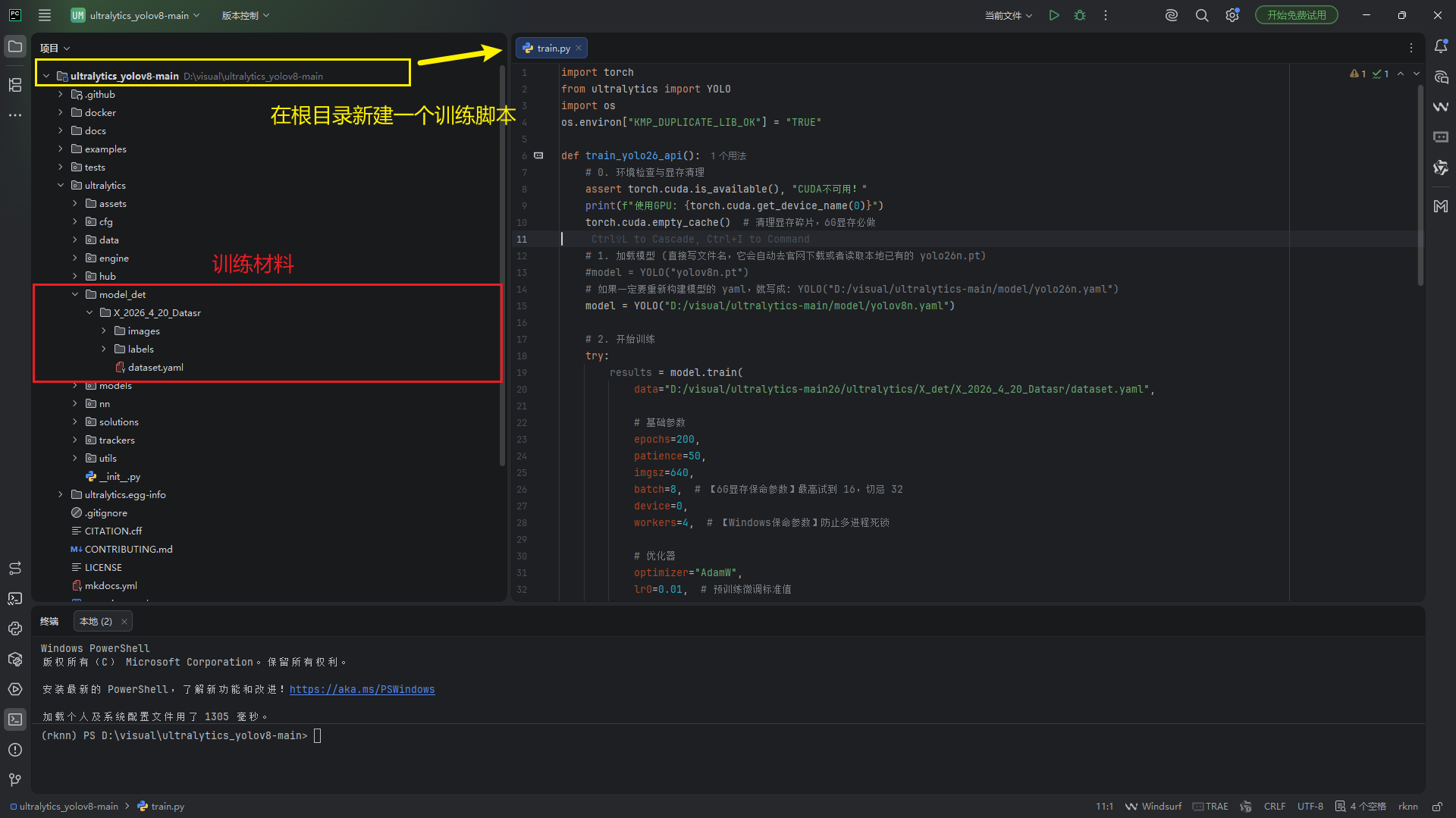
<1.6> 准备模型训练内容,在ultralytics_yolov8-main\ultralytics新建一个文件夹model_det
注:(此处训练可以按照自己正常训练的方法去训练,不必参照我的方法)
- 照片标注软件推荐:X-AnyLabeling:数据轻松标注
model_det //训练内容存放文件夹
└─ X_2026_4_20_Datasr //单独一个模型的文件训练内容
├─ dataset.yaml //yaml参数注明
├─ labels
│ ├─ train.cache
│ ├─ val
│ │ ├─ 2026_04_15_lemon_0.txt
│ │ ├─ ...
│ │ └─ 2026_04_15_lemon_90.txt
│ └─ train
│ ├─ 2026_04_15_lemon_1.txt
│ ├─ ...
│ └─ 2026_04_15_lemon_99.txt
└─ images
├─ val
│ ├─ 2026_04_15_lemon_0.jpg
│ ├─ ...
│ └─ 2026_04_15_lemon_90.jpg
└─ train
├─ 2026_04_15_lemon_1.jpg
├─ ...
└─ 2026_04_15_lemon_99.jpg
dataset.yaml内容如下:
path: D:/visual/ultralytics-main26/ultralytics/model_det/X_2026_4_20_Datasr # 数据集根目录的路径
# 训练集配置
train:
images:
- images/train/
labels:
- labels/train/
# 验证集配置
val:
images:
- images/val/
labels:
- labels/val/
nc: 1 # 类别数量
names: ['lemon'] # 类别名称列表
<1.7 >构建训练脚本,在根目录新建一个train.py脚本,内容如下(参数可以自行调整)
import torch
from ultralytics import YOLO
import os
os.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE"
def train_yolo26_api():
# 0. 环境检查与显存清理
assert torch.cuda.is_available(), "CUDA不可用!"
print(f"使用GPU: {torch.cuda.get_device_name(0)}")
torch.cuda.empty_cache() # 清理显存碎片
# 1. 加载模型 (直接写文件名,它会自动去官网下载或者读取本地已有的 yolov8n.pt)
model = YOLO("yolov8n.pt")
# 如果一定要重新构建模型的 yaml,就写成: YOLO("D:/visual/ultralytics-main/model/yolov8n.yaml")
#model = YOLO("D:/visual/ultralytics_yolov8-main/model/yolov8n.yaml")
# 2. 开始训练
try:
results = model.train(
data="D:/visual/ultralytics_yolov8-main/ultralytics/model_det/X_2026_4_20_Datasr/dataset.yaml",
# 基础参数
epochs=200,
patience=50,
imgsz=640,
batch=8,
device=0,
workers=4,
# 优化器
optimizer="AdamW",
lr0=0.01, # 预训练微调标准值
lrf=0.01,
cos_lr=True,
warmup_epochs=3,
weight_decay=0.05,
# 策略 (已剔除废弃的 label_smoothing)
close_mosaic=10,
amp=True, # 自动混合精度,省显存
# 增强参数 (保留了你精细化的调参,但去掉了吃显存的 copy_paste)
hsv_h=0.015,
hsv_s=0.7,
hsv_v=0.4,
degrees=10,
translate=0.1,
scale=0.5,
shear=5,
perspective=0.0005,
flipud=0.0,
fliplr=0.5,
mosaic=1.0,
mixup=0.1,
copy_paste=0.0, # 【6G显存必关】否则必报 CUDA OOM
# 其他
seed=42,
exist_ok=True,
name="myexperiment_W_A2",
verbose=True
)
print("\n✅ 训练成功完成!")
except RuntimeError as e:
if "out of memory" in str(e).lower():
print("\n❌ 显存溢出(OOM)!请将上面的 batch 改小 (比如改为 4),或者关闭 mixup。")
else:
print(f"\n❌ 训练发生运行错误: {e}")
except Exception as e:
print(f"\n❌ 训练失败: {e}")
if __name__ == "__main__":
train_yolo26_api()
<1.8>(可选)需要重新构建新的模型,是需要yolov8n.yaml文件,需要自己去网上下载,放在对应的位置。
下载地址:ultralytics/ultralytics/cfg/models/v8/yolov8.yaml
<1.9> 可能遇到的问题:
<1.9.1> 运行训练脚本” 提示CUDA不可用!” 解决的思路
- 脚本用的是GPU训练,需要CUDA和PyTorch的环境安装支持,检查是否安装与版本问题。
- 检查PyTorch是否可能安装成cpu版本的。
- 改脚本,直接换成”CPU”训练。
<1.9.2> 实际目录ultralytics_yolov8-main 训练脚本运行时Ultralytics 解析成了ultralytics-yolov8-main
问题:Ultralytics 内部路径处理时,把
_替换成了-,解决:文件夹名改为ultralytics-yolov8-main注:文件夹如果改了目录名,需要重复1.4的开发者模式重新安装
ultralytics
二、转换onnx
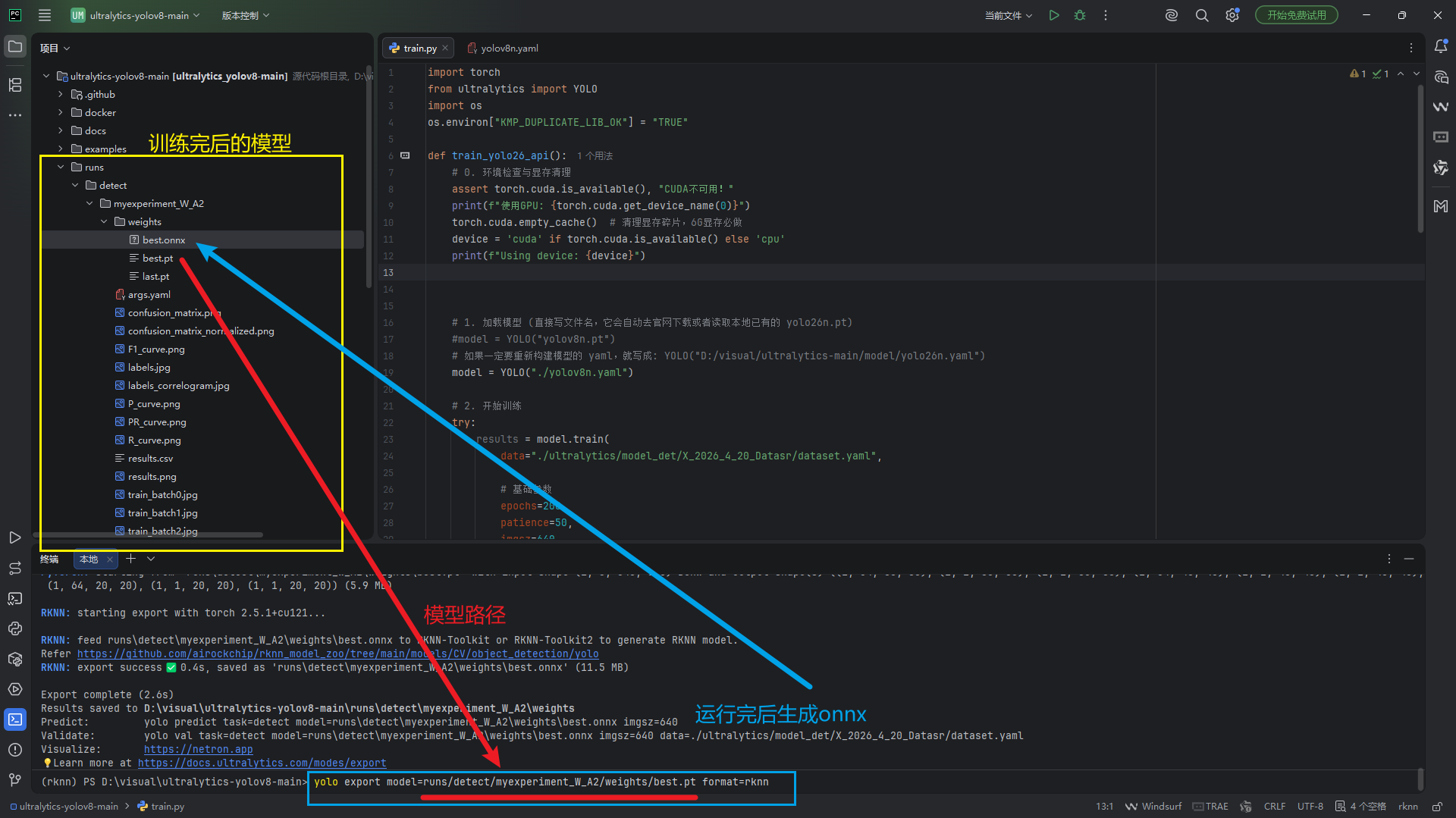
<2.1> 转换:使用命令行导出,在根目录终端输入:
yolo export model=runs/detect/myexperiment_W_A2/weights/best.pt format=rknn
<2.2> 验证:生成的onnx ,使用Netron神经模型查看器检查输出头是否有问题
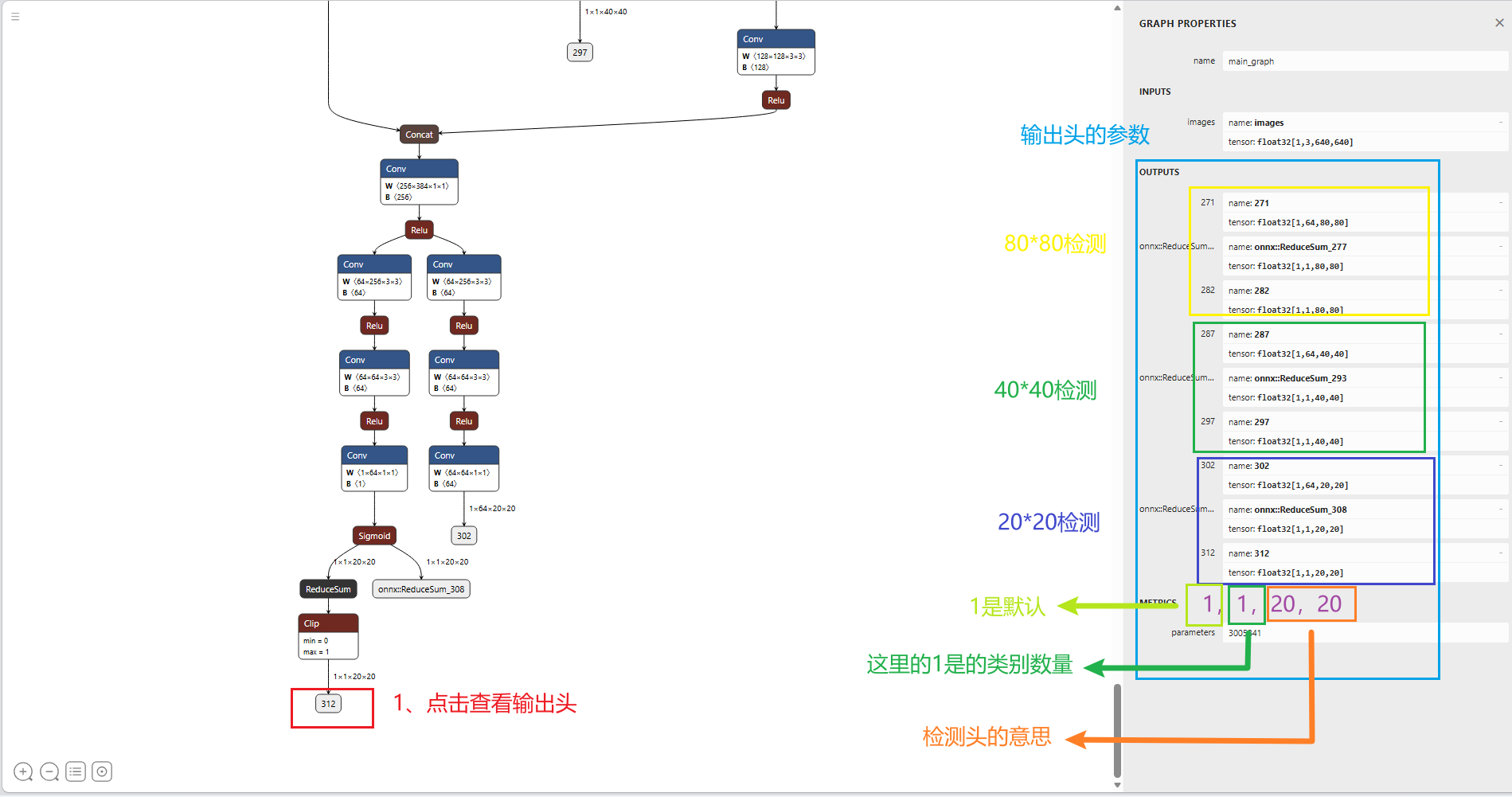
YOLOv8在RKNN转换过程中检测到,三个分支的80×80检测头,40×40检测头,20×20检测头,模型结构才为正确。
三、转换rnkk
3.1环境准备
注:需要使用到linux环境的工具链
<3.1.1>我这里使用的是win11系统,我是直接去使用win11自带的WSL2系统,(使用虚拟机安装ubuntu系统也可以)
- 加速器加速微软商店,搜素ubuntu22.04,直接安装即可
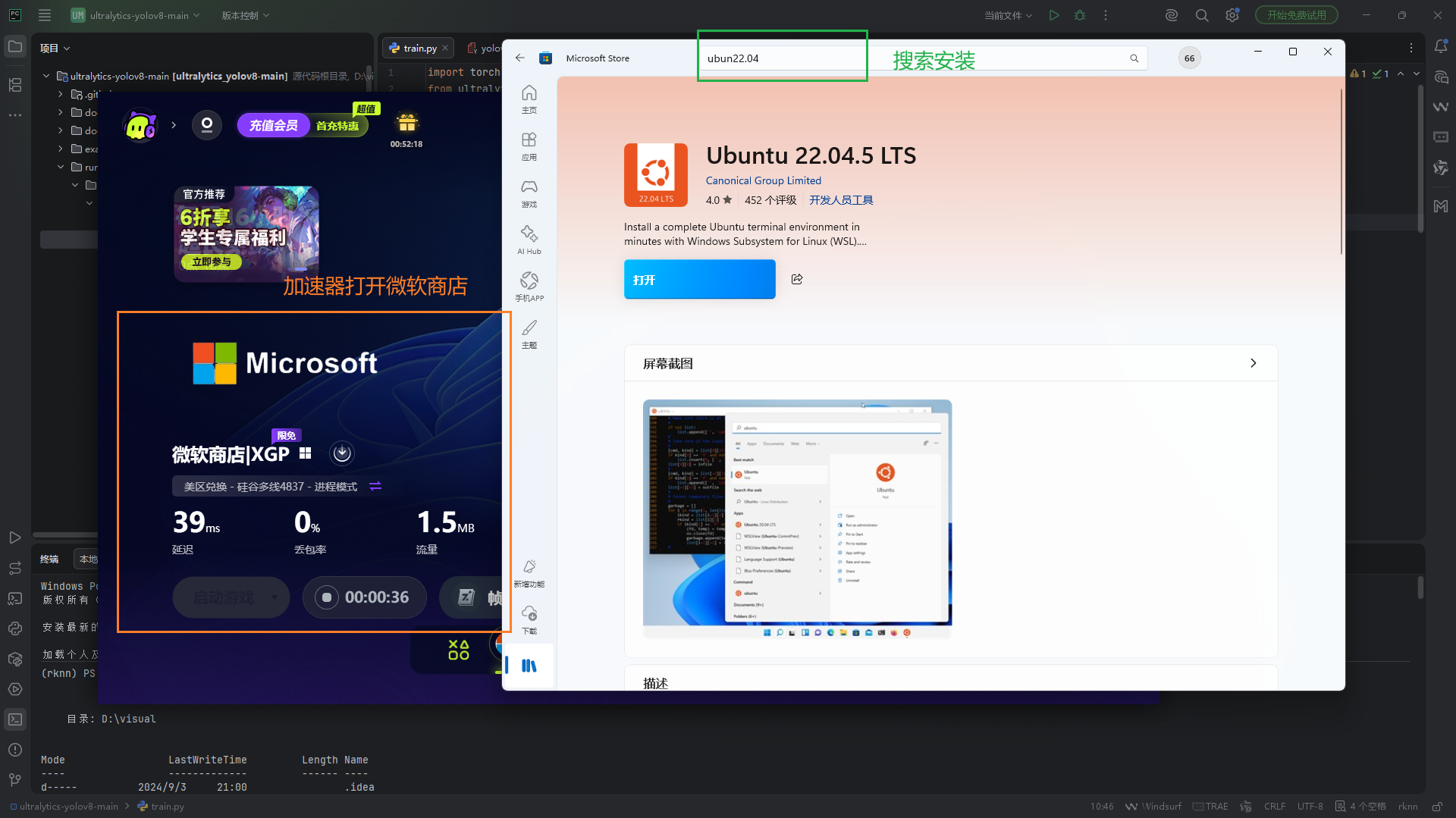
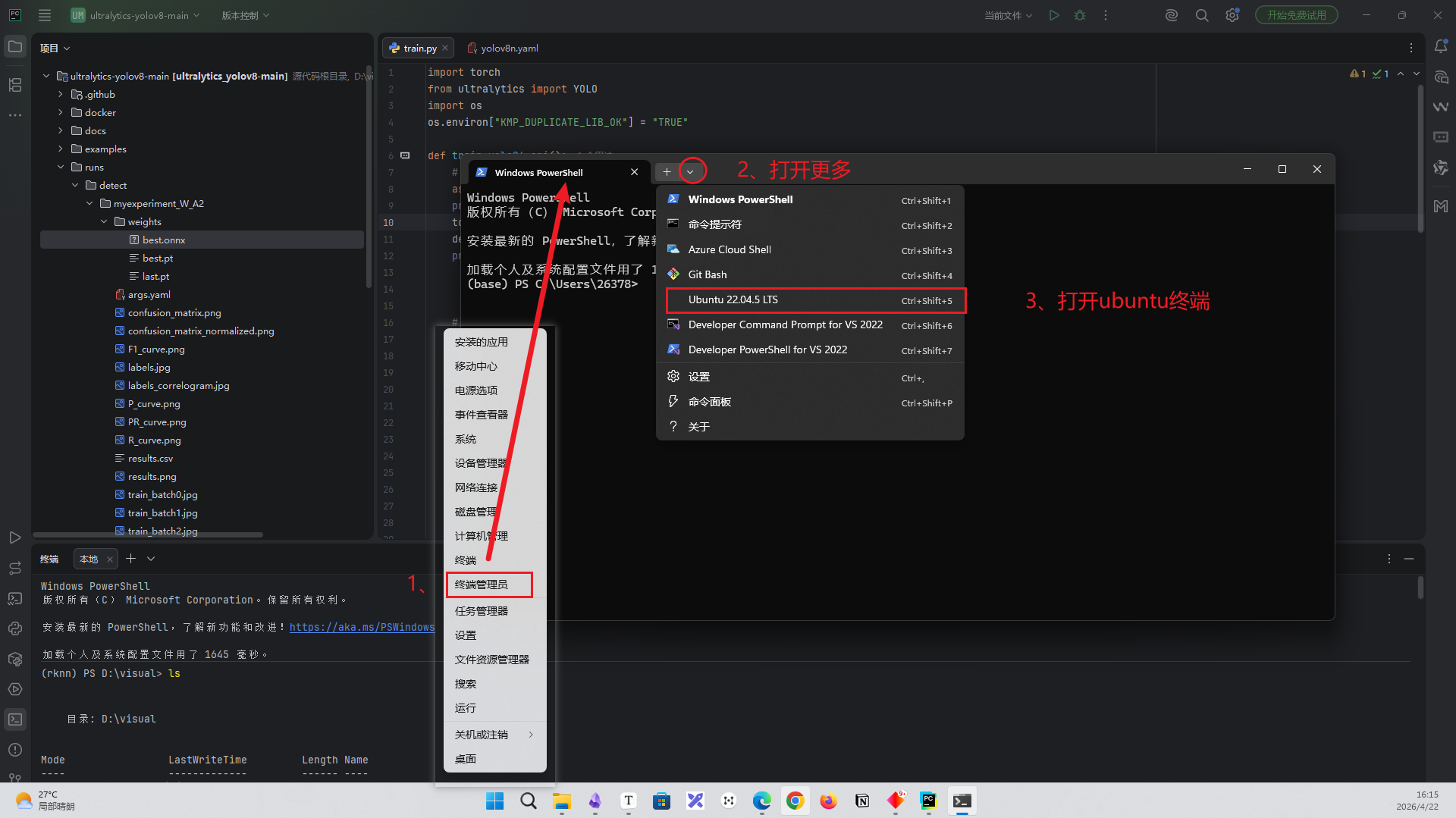
<3.1.2>打开ubuntu22.04系统:点击win图标->终端管理员->选择更多->打开ubuntu22.04
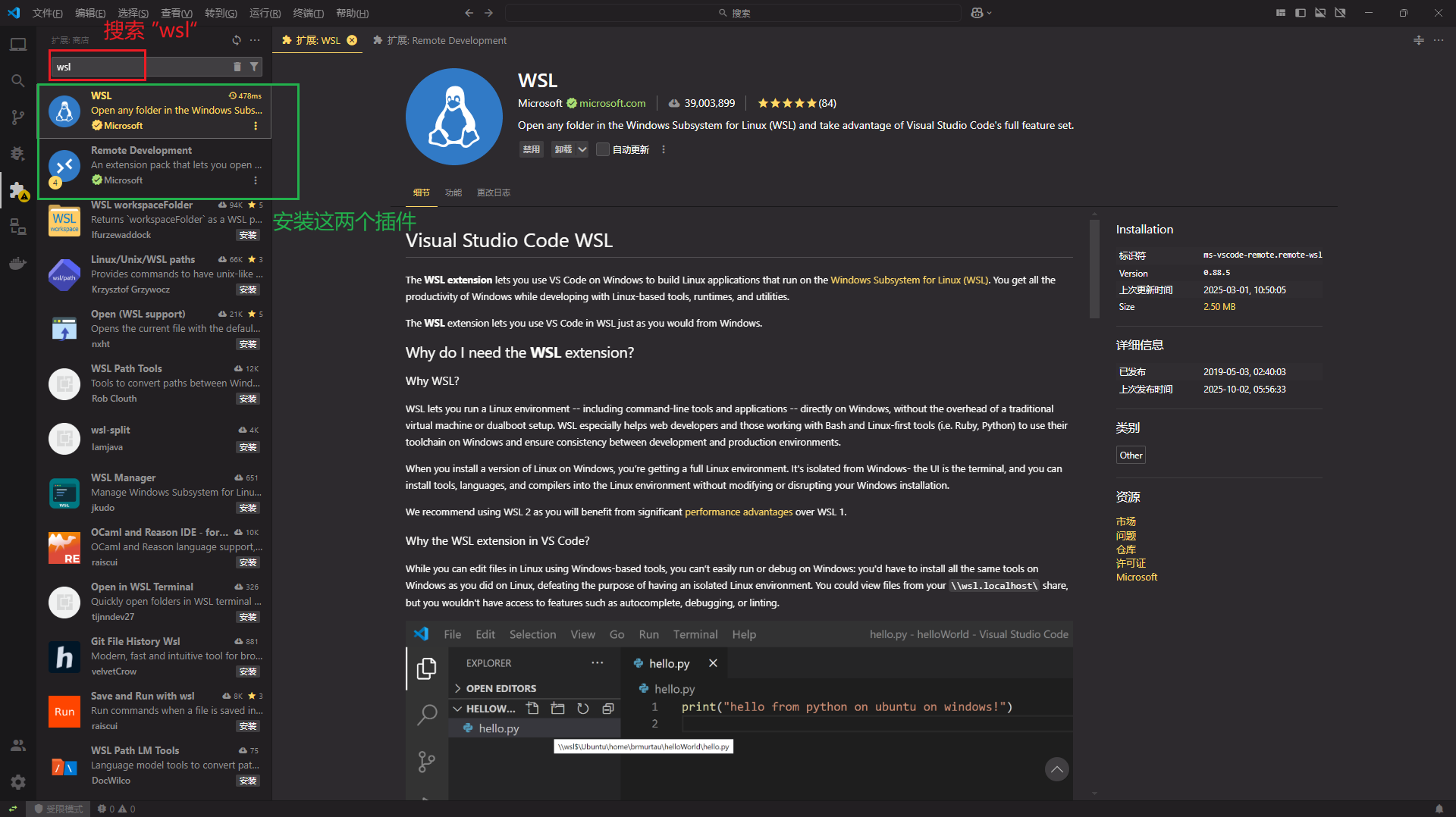
<3.1.3> 编辑器IDE连接到ubuntu系统:打开 Visual Studio Code 下载插件 搜索”WSL“,安装相连的两个插件
打开远程选择用户连接,连接到ubuntu系统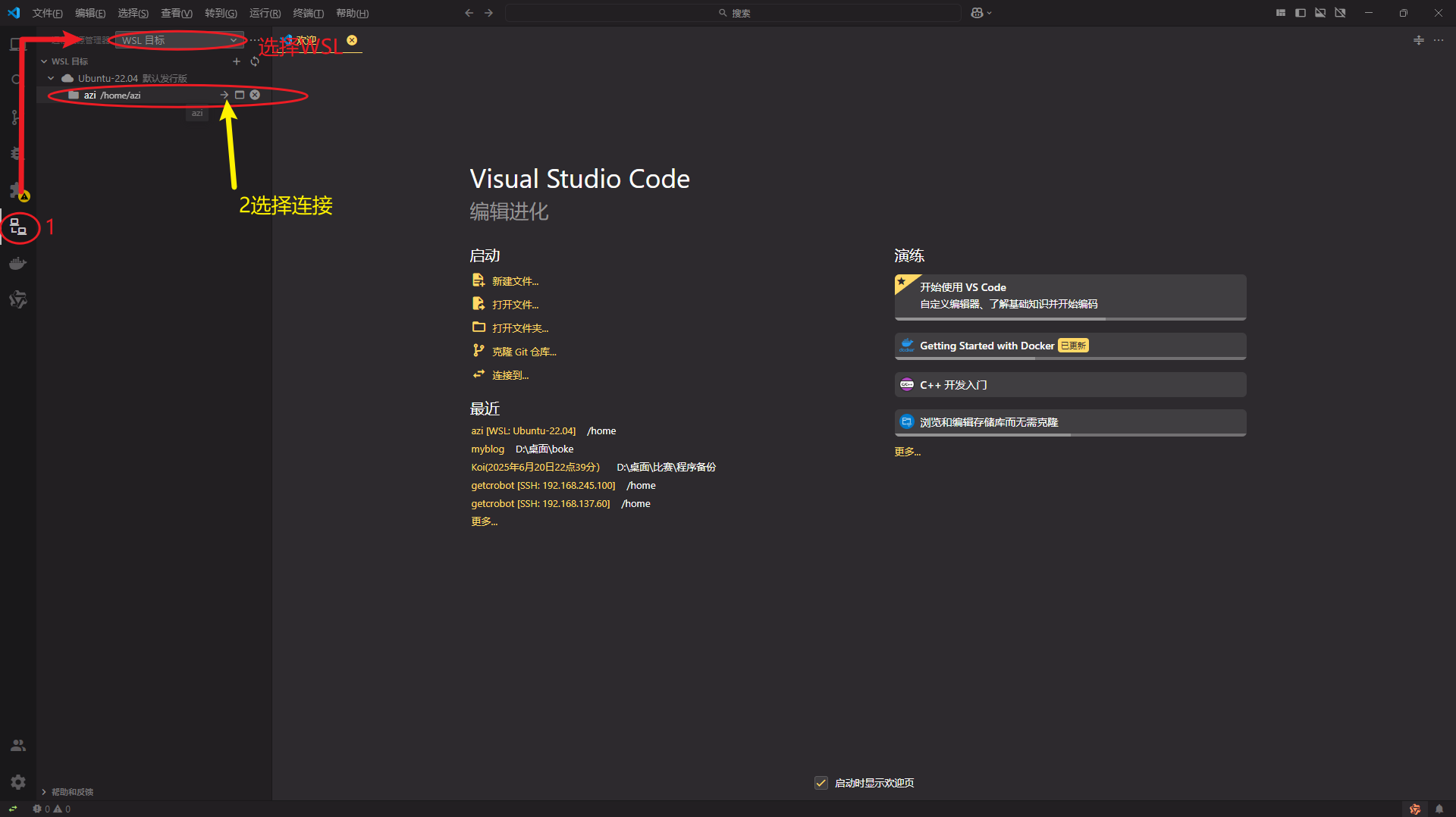
<3.1.4> ubuntu22.04安装conda环境(可选,不一定要用虚拟环境)
# 下载
wget https://repo.anaconda.com/archive/Anaconda3-2024.10-1-Linux-x86_64.sh
# 安装
bash Anaconda3-2024.10-1-Linux-x86_64.sh
# 激活
source ~/.bashrc
conda --version
# 创建环境
conda create -n rknn_tools python=3.10
# 激活环境
conda activate rknn_tools
<3.1.5> rknn-toolkit2环境与rknn_model_zoo程序
本地下载从vscode拖进来文件夹或者使用git clone远程拉取都可以
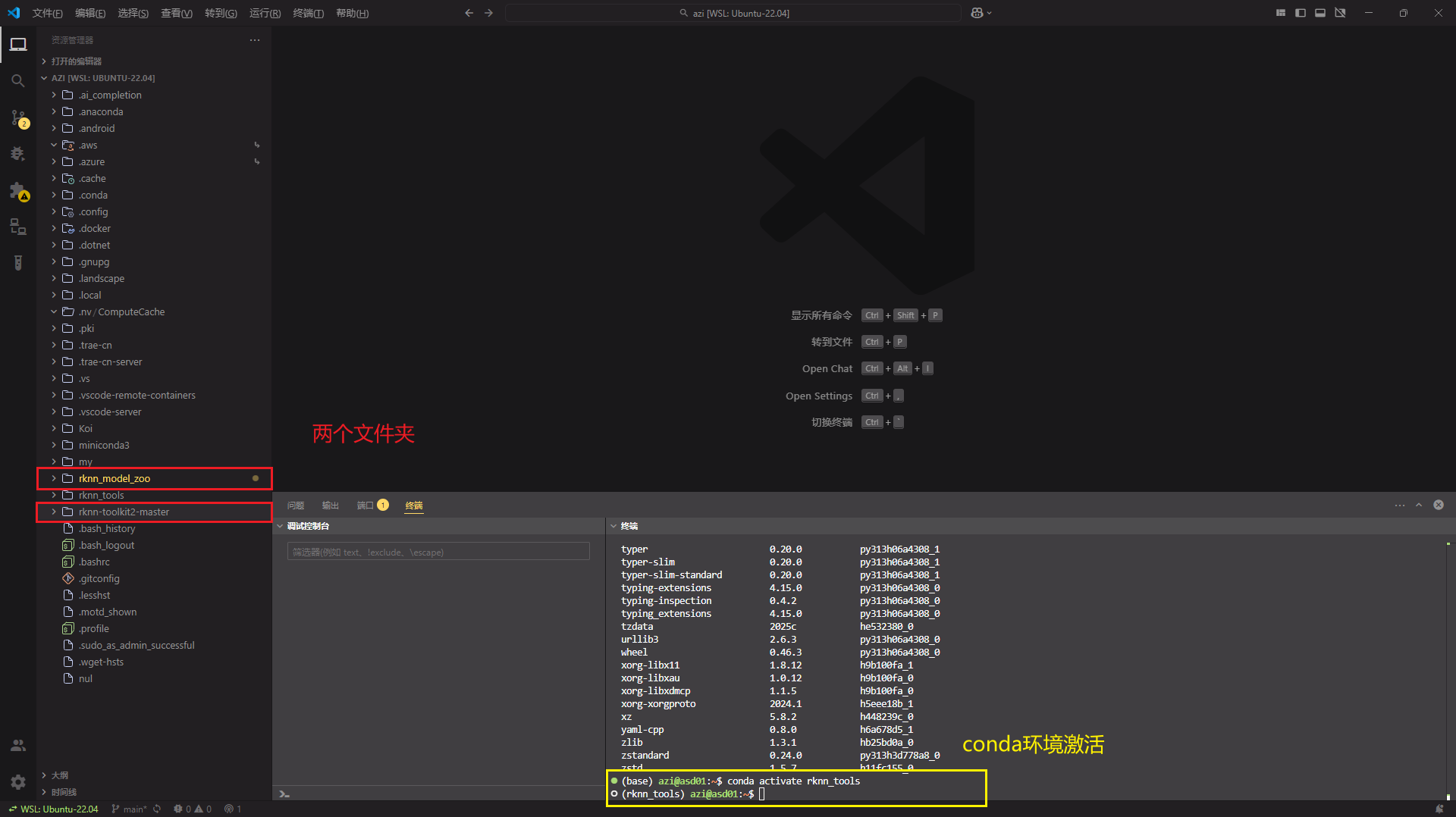
环境配置:rknn-toolkit2/packages/路径下有arm64和x86_64需要看清你的cpu是什么架构的进行选择
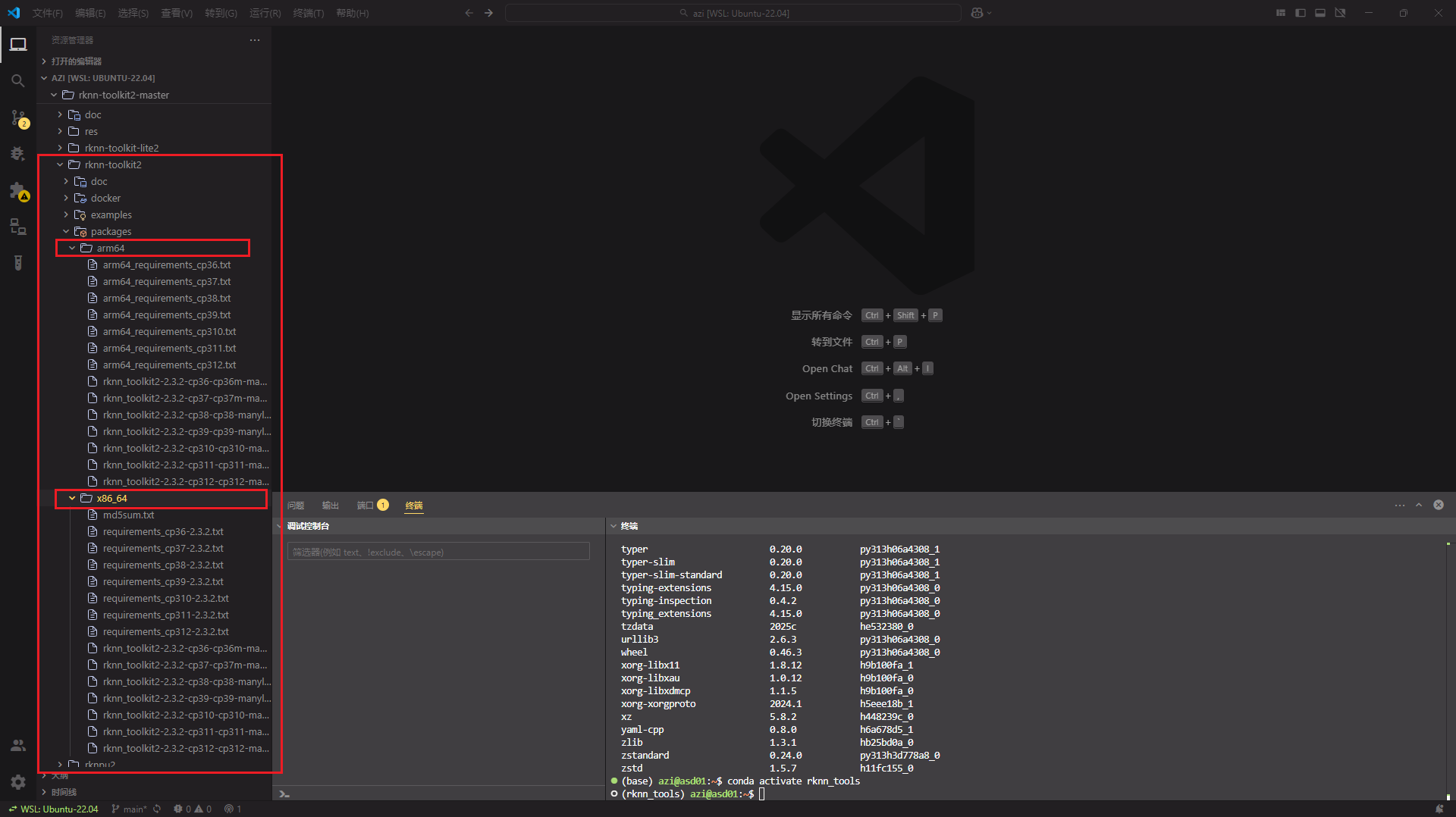
以我的x86电脑为例,终端进入对应的x86_64文件路径,输入命令行

安装pip依赖库
pip install -r requirements_cp310-2.3.2.txt
安装工具
pip install rknn_toolkit2-2.3.2-cp310-cp310-manylinux_2_17_x86_64.manylinux2014_x86_64.whl
注:其中的cp310是python环境版本号,要选择对应的版本号
3.2 文件修改
进入rknn_model_zoo/examples/yolov8/python/下的文件夹:
- 修改
yolov8.py的代码里的变量CLASSES 与 coco_id_list,__main__主程序里面芯片型号改为rk3588
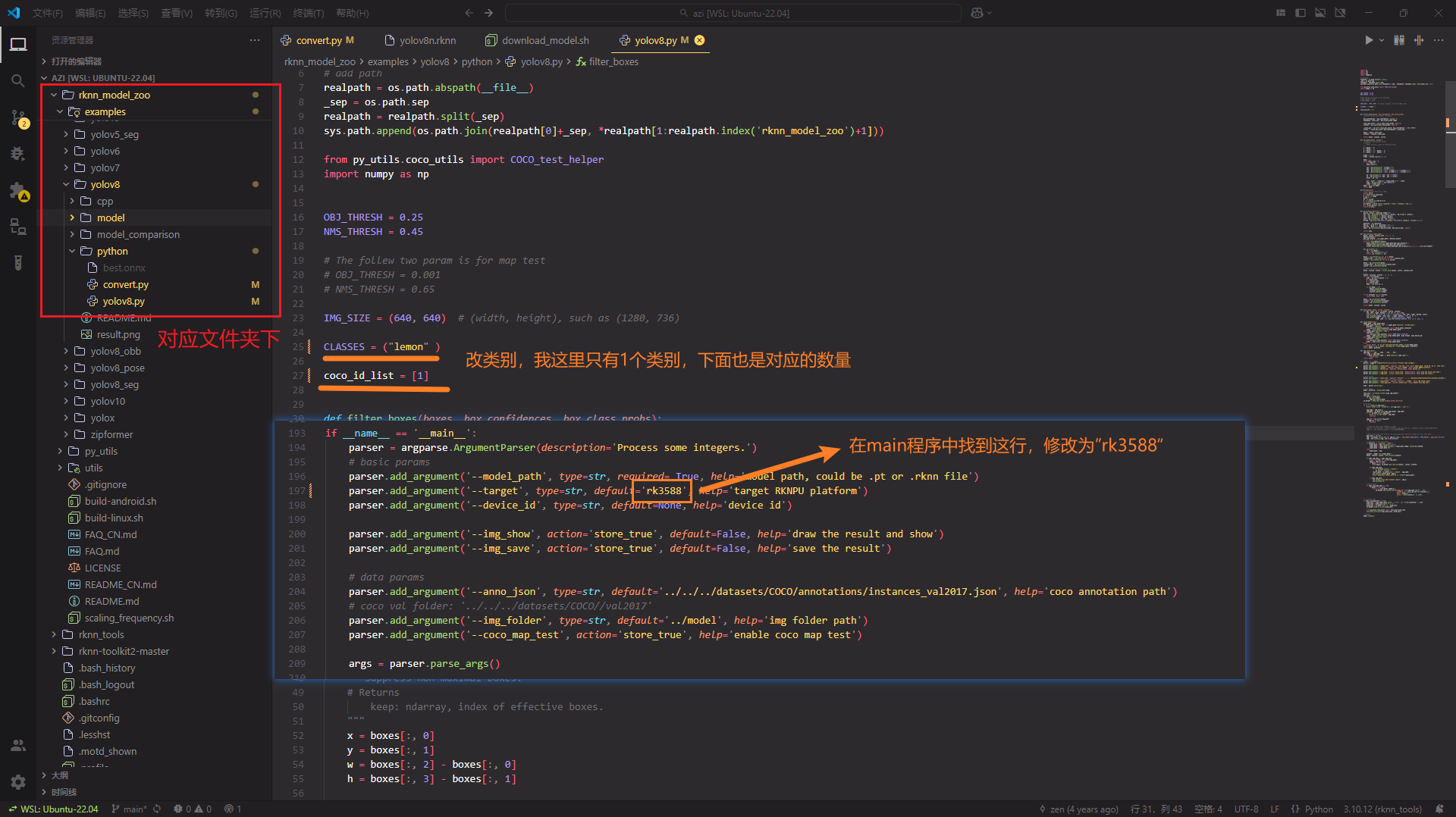
- 修改
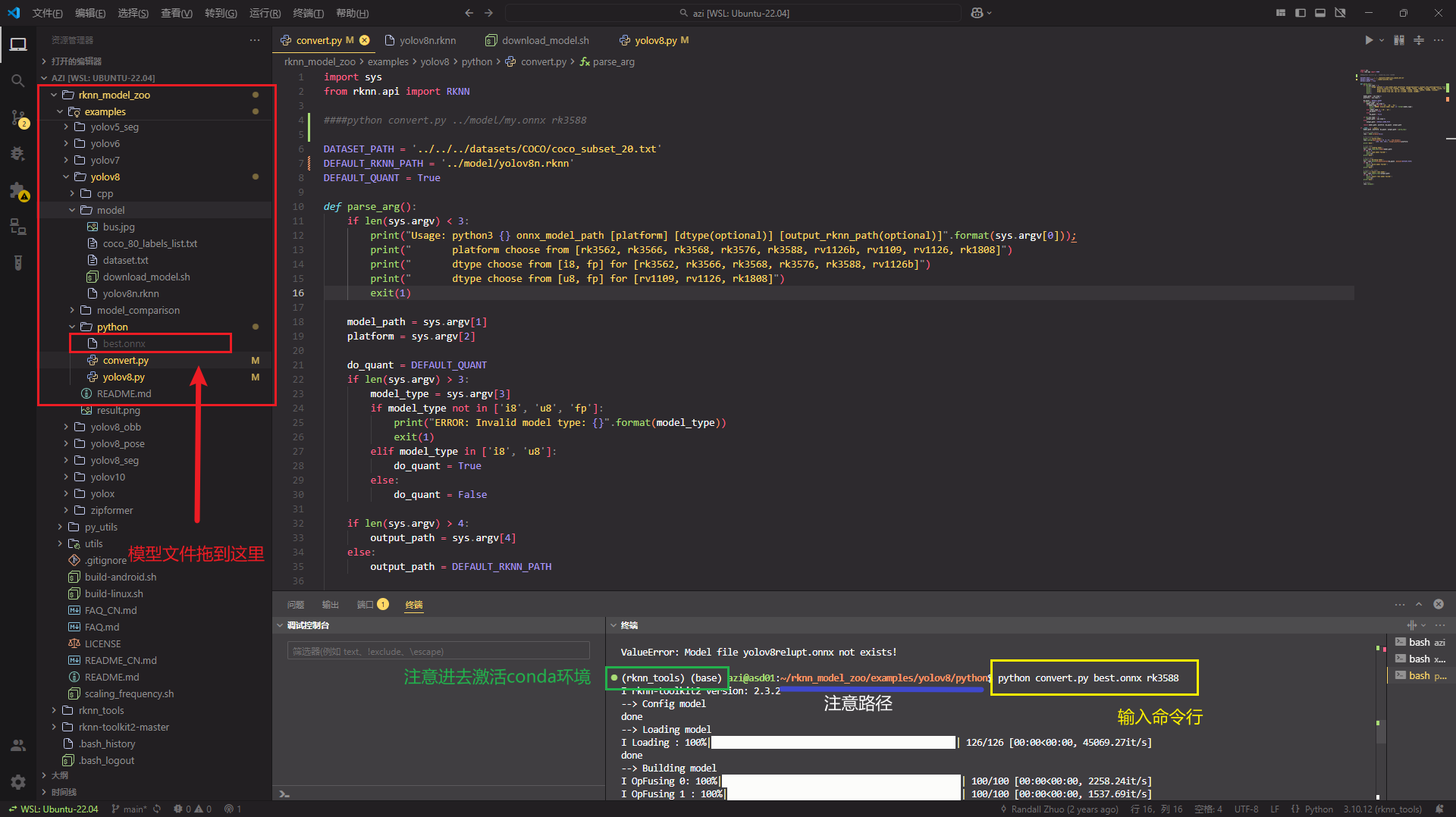
convert.py的代码的变量DEFAULT_RKNN_PATH是存放位置
DEFAULT_RKNN_PATH = '../model/yolov8n.rknn'
3.3 模型转换
把转换后的onnx模型拖到rknn_model_zoo/examples/yolov8/python/文件夹中,跟修改后文件同级
终端进去rknn_model_zoo/examples/yolov8/python/路径下输入
python convert.py best.onnx rk3588
四、开发板部署
开发板:香橙派5max | 系统:Ubuntu22.04 | 代码环境:ROS2
ROS2 部署:gzcnb/ROS2_YOLOv8_RK3588_object_detect: 支持调用rk3588是yolov8视觉检测的ros2环境包
4.1环境准备
ROS2环境安装:ubuntu系统安装ROS(简单版)V2
opencv安装命令行
sudo apt update & sudo apt install libopencv-dev python3-openc
4.2rknn环境配置
<4.2.1> 下载ROS2功能包放入ros2_ws/src的路径,路径如下
ros2_ws
├─ build
├─ install
├─ log
└─ src
└─ yolov8_detect_rknn_pkg
├─ CMakeLists.txt #编译信息文件
├─ package.xml
├─ src
│ ├─ img_detect_node.cpp #图片检测
│ └─ video_detect_node.cpp #摄像头检测
├─ model
│ ├─ lemon_100.jpg
│ ├─ result_bus.jpg
│ ├─ yolov8n.rknn #存放检测模型的地方
│ └─ librknn_api #动态链接库暂时存放的地方
│ ├─ armhf-uclibc
│ │ ├─ librknnmrt.a
│ │ └─ librknnmrt.so
│ ├─ armhf
│ │ └─ librknnrt.so
│ └─ aarch64
│ └─ librknnrt.so
└─ include #需要用到头文件
├─ rknn_api.h
├─ rknn_custom_op.h
└─ rknn_matmul_api.h
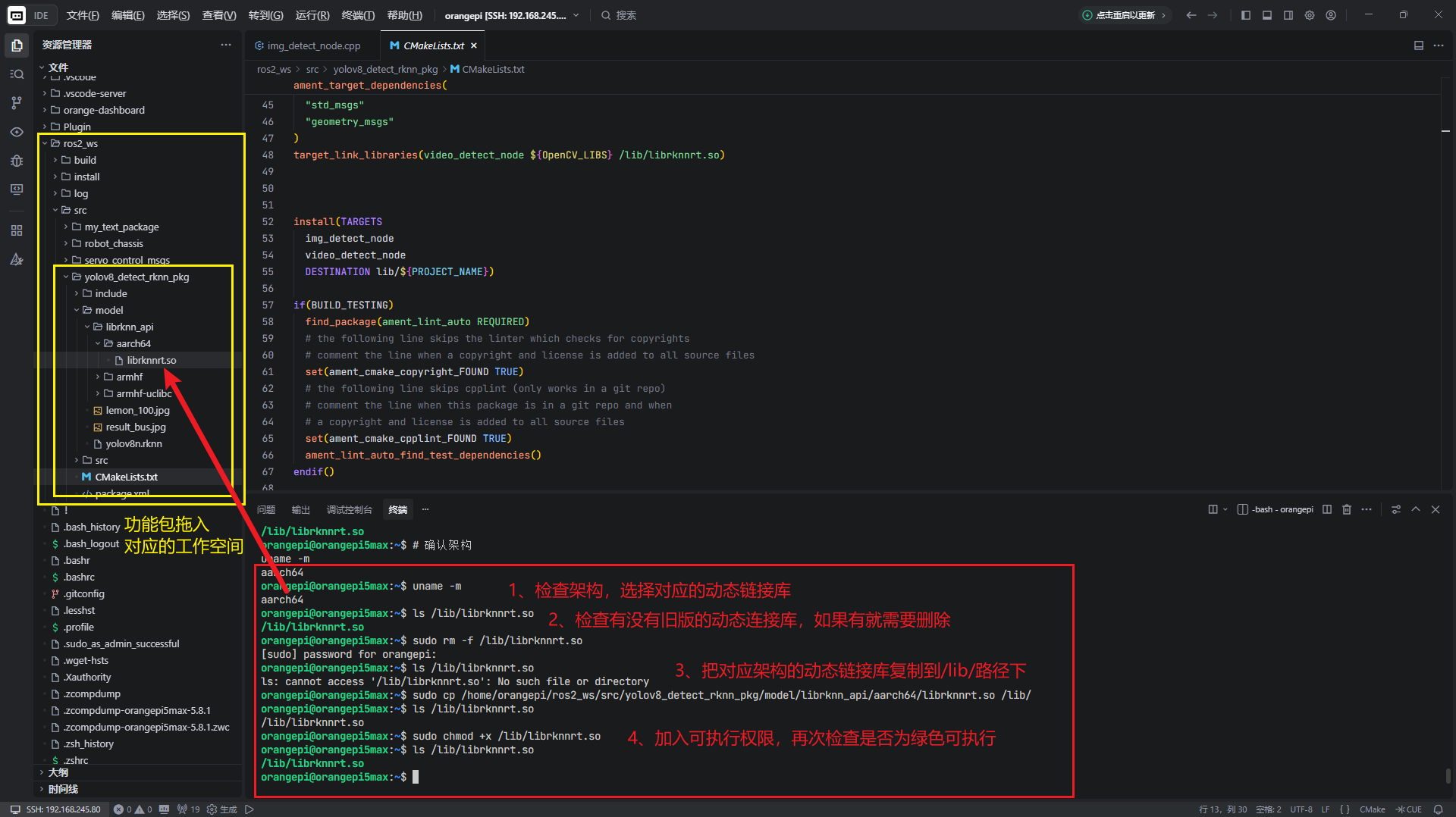
<4.2.2> 检测开发版的架构的,使用对应的动态链接库
##检测架构命令行。
uname -m
##检查/lib/下原先是否有动态链接库。
ls /lib/librknnrt.so
##/lib/下原有动态链接库,需要删除。
sudo rm -f /lib/librknnrt.so
##复制对应的的架构的动态链接库进去/lib/【需要修改为你开发板的librknnrt.so的绝对路径】
sudo cp /home/orangepi/ros2_ws/src/yolov8_detect_rknn_pkg/model/librknn_api/aarch64/librknnrt.so /lib/
##加入可执行的权限。
sudo chmod +x /lib/librknnrt.so
4.3图片检测
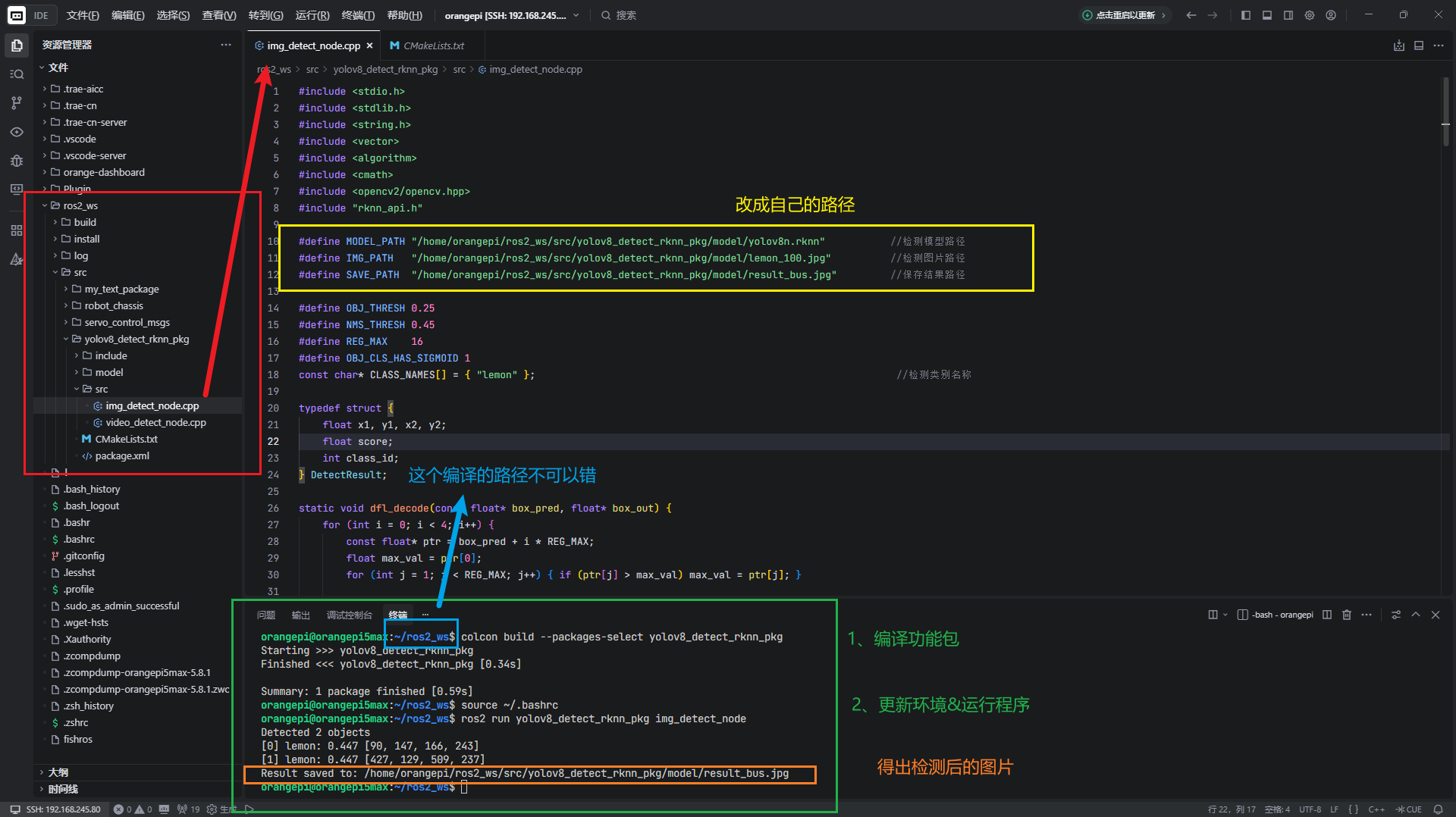
1、yolov8_detect_rknn_pkg/src/img_detect_node.cpp是图片检测程序【修改成你自己对应的路径】
#define MODEL_PATH "/home/orangepi/ros2_ws/src/yolov8_detect_rknn_pkg/model/yolov8n.rknn" //检测模型路径
#define IMG_PATH "/home/orangepi/ros2_ws/src/yolov8_detect_rknn_pkg/model/lemon_100.jpg" //检测图片路径
#define SAVE_PATH "/home/orangepi/ros2_ws/src/yolov8_detect_rknn_pkg/model/result_bus.jpg" //保存结果路径
2、终端进去ros2_ws工作空间路径下,进行编译
colcon build --packages-select yolov8_detect_rknn_pkg
3、运行ros2图片检测
source ~/.bashrc
ros2 run yolov8_detect_rknn_pkg img_detect_node
4.4摄像头检测
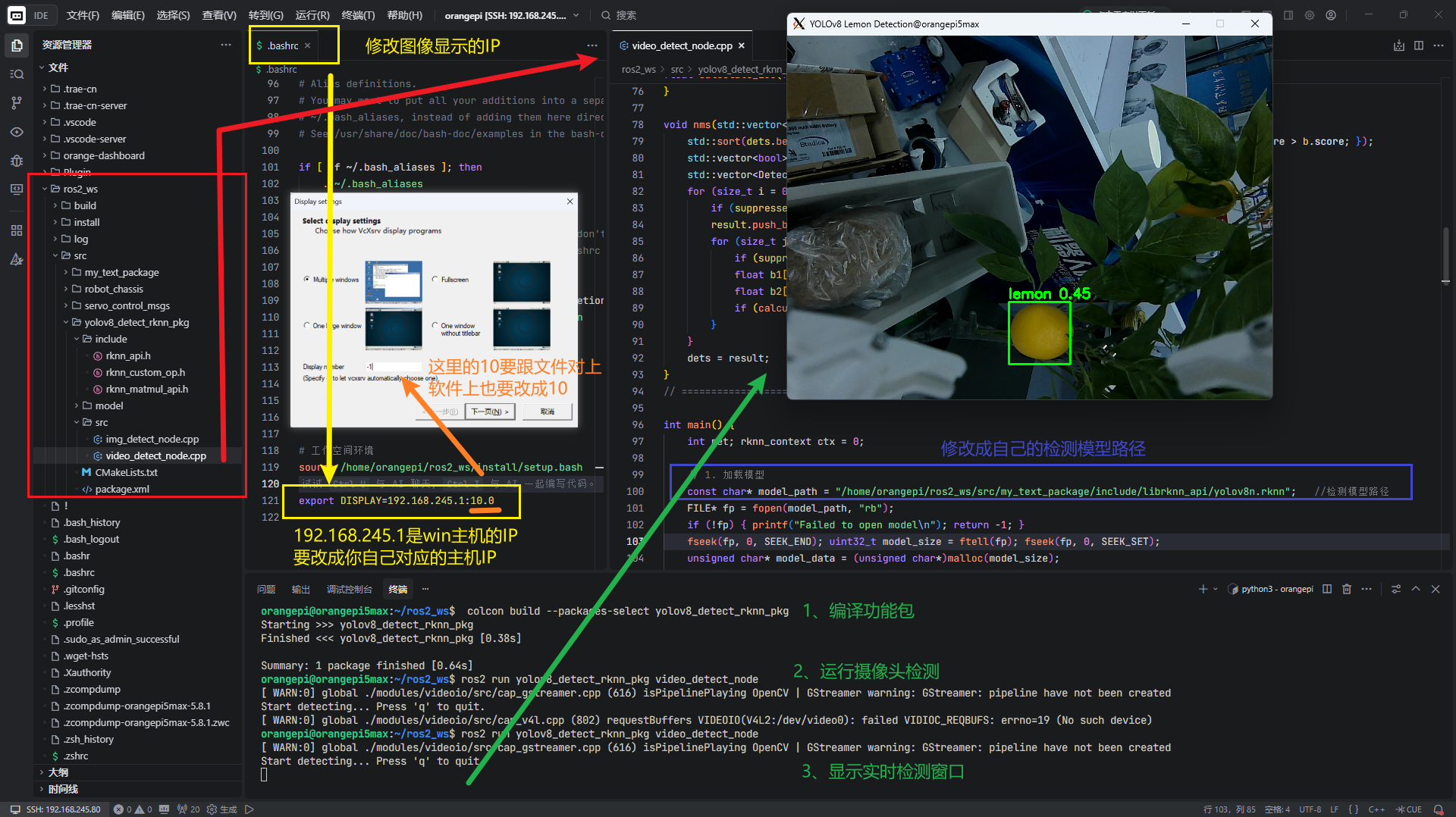
环境前提:开发板一般安装服务器版本,没有后端,我这里用的是PC电脑ssh远程连接到开发板ubuntu
显示原理
Linux 程序 (OpenCV imshow) → X11 协议 → Windows XLaunch 显示
(服务器端) (网络) (客户端显示)
Windows 安装 XLaunch:https://sourceforge.net/projects/vcxsrv/
linux的
~/.bashrc文件最后一行添加export DISPLAY=192.168.1.100:0.0 #win显示端主机的IP:端口
开始检测:
1、yolov8_detect_rknn_pkg/src/video_detect_node.cpp是摄像头检测程序【main程序修改成你自己对应的检测模型路径】
const char* model_path = "/home/orangepi/ros2_ws/src/my_text_package/include/librknn_api/yolov8n.rknn";
2、终端进去ros2_ws工作空间路径下,进行编译
colcon build --packages-select yolov8_detect_rknn_pkg
3、运行ros2摄像头检测
source ~/.bashrc
ros2 run yolov8_detect_rknn_pkg video_detect_node
纯C++部署参考(只能图片检测):A7bert777/YOLOv8_RK3588_object_detect:YOLOv8_RK3588_object_detect
参考文章:
【YOLOv8部署至RK3588】模型训练→转换RKNN→开发板部署_yolov8转rknn-CSDN博客